Cloudflare Exposes Perplexity AI’s Stealth Crawlers: Bypassing Blocks in Broad Daylight

Cloudflare drops a bombshell—Perplexity AI allegedly deployed shadow crawlers to skirt website restrictions. Who needs ethics when you've got growth targets to hit?
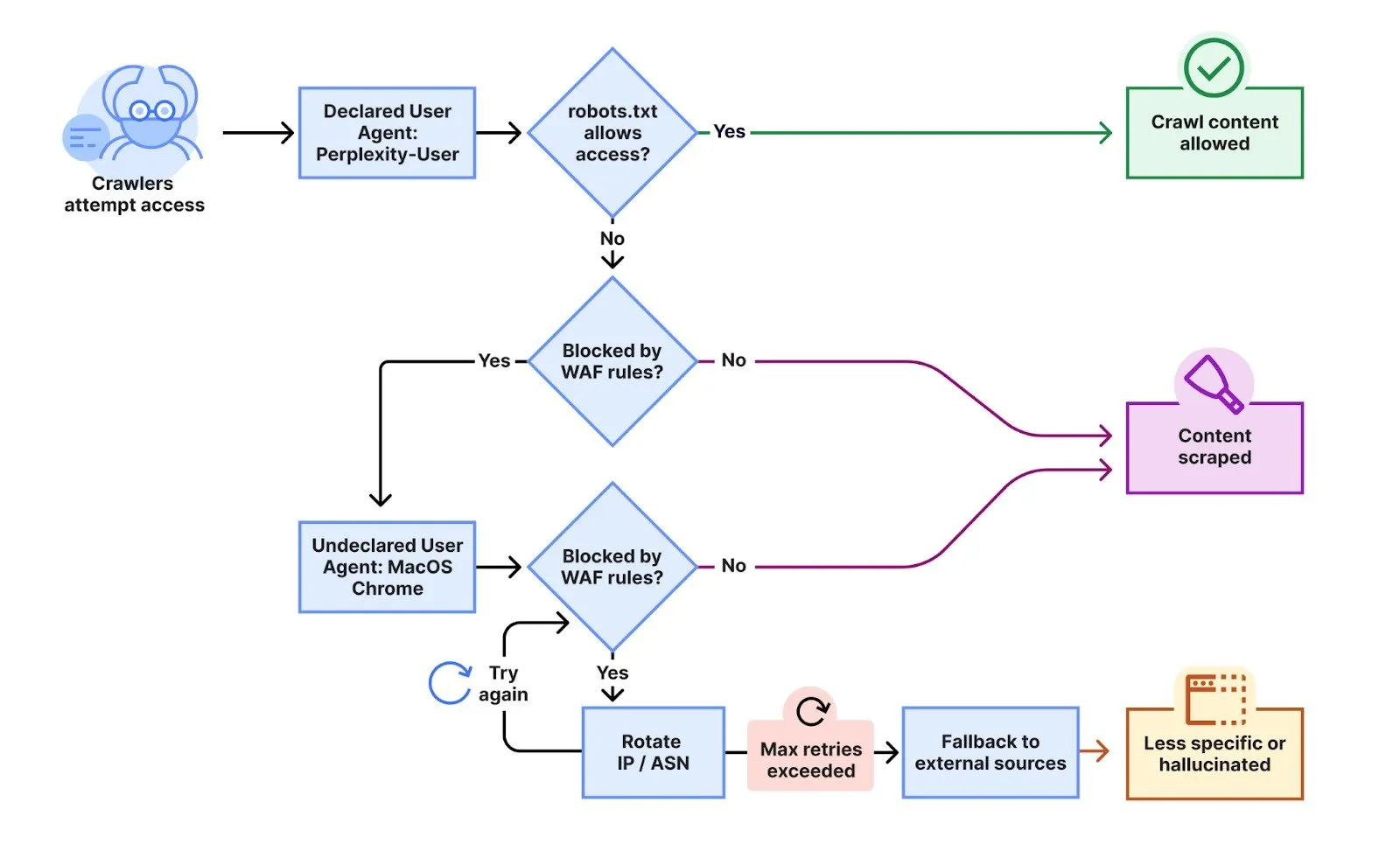
How the stealth crawl works: The AI firm's bots reportedly masked identities to scrape data from Cloudflare-protected sites. No blockchain required—just old-fashioned deception dressed as innovation.
The cybersecurity showdown: Cloudflare's radar caught what Perplexity thought was invisible traffic. Turns out when you're moving $10B in VC money, someone always notices the footprints.
Silicon Valley's open secret: Another 'disruptor' treating rules as speed bumps. But hey—at least they didn't ICO their way out of this one.
 Source: Cloudflare
Source: Cloudflare
The stealth crawlers employed sophisticated evasion techniques. "This undeclared crawler utilized multiple IPs not listed in Perplexity's official IP range, and WOULD rotate through these IPs in response to the restrictive robots.txt policy and block from Cloudflare. In addition to rotating IPs, we observed requests coming from different ASNs in attempts to further evade website blocks."
According to Cloudflare, Perplexity's “declared” crawlers—the ones that are easily identifiable—generate 20-25 million requests daily, while the undeclared stealth crawlers—those which rely on shady tactics to hide their purpose—add another 3-6 million requests per day. "This activity was observed across tens of thousands of domains and millions of requests per day."
The company did not respond to Decrypt's request for comment. A spokesman dismissed the allegations to TechCrunch as nothing more than a Cloudflare “sales pitch.”
Cloudflare CEO Matthew Prince has been vocal about what he sees as AI companies' unsustainable extraction of web content. "Search traffic referrals have plummeted as people increasingly rely on AI summaries." In July, he revealed devastating ratios: while Google sends one visitor for every 18 pages it crawls, AI companies are far worse. OpenAI's ratio deteriorated from 250-to-1 six months ago to 1,500-to-1 today. Anthropic's numbers are even more extreme, jumping from 6,000-to-1 to 60,000-to-1 in the same period.

This prompted Cloudflare to launch what it calls "Content Independence Day," defaulting to blocking AI crawlers for all new domains, becoming the de-facto vigilante protecting content creators from the threats of pesky AI crawlers.
As Decrypt previously reported, more than a million websites had already opted into blocking since last fall, with major publishers including the Associated Press, Time, The Atlantic, BuzzFeed, Reddit, Quora, and Universal Music Group joining the movement.
"There are clear preferences that crawlers should be transparent, serve a clear purpose, perform a specific activity, and, most importantly, follow website directives and preferences," Cloudflare stated. The company contrasted Perplexity's behavior with OpenAI, which it said properly respects robots.txt files and stops crawling when blocked.
Cloudflare's response includes both immediate technical measures and longer-term initiatives. The company has deployed signature matches for the stealth crawler into its managed rules, available to all customers including free users. It's also developing tools like an "AI Labyrinth," which traps non-compliant bots in mazes of fake content, and a "pay-per-crawl" marketplace that would allow publishers to charge AI companies for access to their content.
